

 开云sports
开云sports
机器之机杼剪部
扩散讲话模子(Diffusion Language Models, DLLMs)因其多种潜在的特色而备受讲理,如能加快的非自回来并行生成特色,能凯旋草拟裁剪的特色,能数据增强的特色。说合词,其模子材干往往过时于同等限度的强力自回来(AR)模子。
近日,华中科技大学和字节最初融合推出了 Stable-DiffCoder。这不单是是一个新的扩散代码模子,更是一次对于 「扩散锻练能否擢升模子材干上限」 的深度探索。
Stable-DiffCoder 在全都复用 Seed-Coder 架构、数据的条目下,通过引入 Block Diffusion 握续预锻练(CPT)及一系列踏实性优化计谋,奏效罢了了性能反超。在 多个 Code 主流榜单上(如 MBPP,BigCodeBench 等),它不仅打败了其 AR 原型,更在 8B 限度下超越了 Qwen2.5-Coder ,Qwen3,DeepSeek-Coder 等一众强力开源模子,讲明了扩散锻练范式自己即是一种宏大的数据增强时刻。

论文标题:Stable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
Github 相接: https://github.com/ByteDance-Seed/Stable-DiffCoder
模子相接: https://huggingface.co/collections/ByteDance-Seed/stable-diffcoder
扩散过程难以高效学习样本学问
扩散过程诚然名义上不错引申好多数据,不错看成一个数据增强的时刻,然则实质上会引入好多噪声致使诞妄学问的学习。
举例底下的例子:
将其 mask 成
不错发现对于终末一个 mask_n,其只可在看见 a=1,b=2 的情况下去学习 a+b=7,会酿成诞妄的学问映射。终末充其量也只可学到,a=3,b=4 在 a+b = 这个语境下的共现概率更大少量,不可学到明确的加法规则。
token 推理的学问和经由设想
论文通过建模这个学问的学习来解释这个感奋:
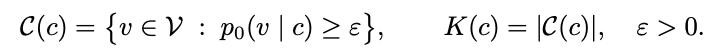
假定 c 是刻下可见的样本,证据确凿区别通过这些样本在刻下位置大致推理出的 token 聚积为 C (c),大小为 K (c)(这里多个 token 同期推理的气象一致,因此只精真金不怕火的探讨单个 token 推理)。由于使用竟然凿区别来界说的,是以 c 越多越干净的时刻,K (c) 越小。

因此,若是用纯双向的扩散过程,在 mask 比例较大的时刻,刻下 token 见到的 c 变小,不干净的概率变大,导致 K (c) 变大,难以映射到明晰的规则。同期其会产生会产生多样各种的 c,平均每个 c 的学习量会减小。另外,还要保证锻练采样的 c 跟推理用的 c 是一致的,才能更好的使用锻练学习的学问。
接下来论文通过在 2.5B 的模子设想试验来进一步阐释并讲明这个论断。论文从一个 AR model 出手化,然后锻练一段新的学问。论文设想了 3 个锻练神气来探索:
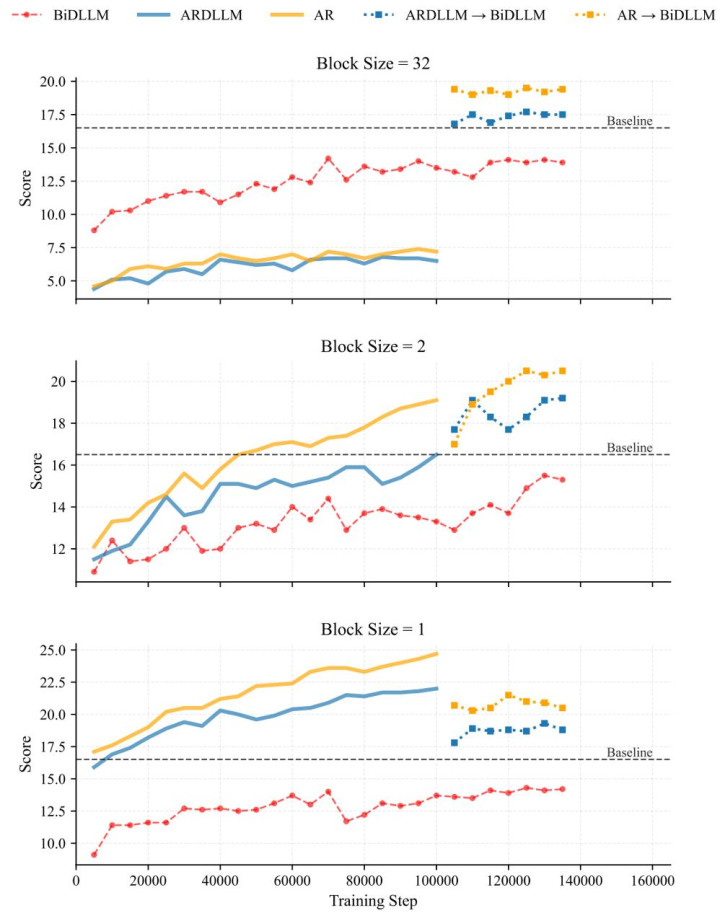
(1)AR->BiDLLM: 用 AR 的神气不竭锻练,在 100k step 的时刻 CPT 成双向的 DLLM。
(2)ARDLLM->BiDLLM: 用 AR 的结构,然则使用纯双向的采样格局来锻练。然后 100k step CPT 成 BiDLLM。
(3)BiDLLM:使用纯双向的 DLLM 锻练。
不错发现,终末后果是(1)>(2)>(3),这也合乎前边的表面。不必立地 [MASK] 的(1)决策对于学问有更快的压缩速率,何况改换成 BiDLLM 也保握着最好性能,这不错讲明在要高效的学好一个 DLLM,不错用 AR 或者小 block size 的 block diffusion 来进行学问压缩。另外意旨兴味意旨兴味的是,在 block=32 时(1)和(2)的发扬比(3)差,开云体育官方网站然则在 100k 之后发扬比(3)好。100k 之前不错证明,AR 采样的 c 跟 block size=32 推理过程的 c 不太匹配,然则由于 AR 压缩了大都灵验的学问,稍稍 CPT 一下就能适配这种推理过程。同期也不错证明,AR 这种结构的先验,可能更适宜 prompt+response 这种从左侧出手推理的过程。
因此咱们将锻练经由设想为,先用 AR 压缩一遍学问,然后用 AR 退火的前一个 checkpoint 不竭 CPT 成小 block 的 block diffusion,来探索 diffusion 过程的数据增强材干。
踏实的 DLLM warmup 计谋握续预锻练设想
扩散模子的握续预锻练往往对超参数的设想(如学习率)非凡敏锐,容易出现 grad norm 的颠倒变高,这也会受到多样锻练架构的影响。为了保握多样锻练架构的学习踏实,以及紊乱的调参过程,团队设想了一种适配的 warmup 计谋。
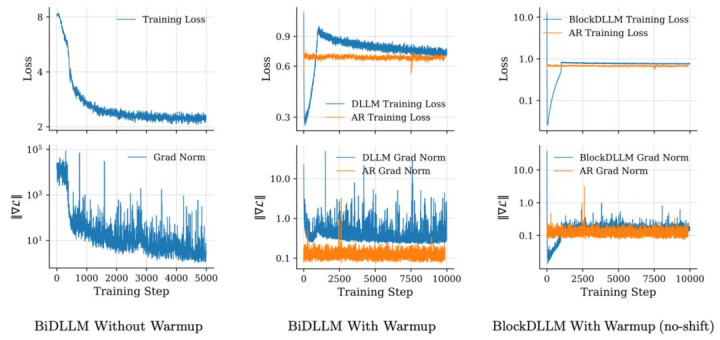
DLLM 的 CPT 过程不踏实主要受到底下 3 个原因影响:
(1)Attention 从单向变成双向
(2)Mask 变多导致任务变得很难
(3)为了对都 ELBO,会在交叉熵前边乘上加权通盘。比如只 mask 了一个 token,会等价于只绸缪了这个 token 的 loss,会大幅增大这个 token 对于梯度的影响,进而影响 grad norm 和 loss。
由于退火 attention 的神气难以天真适配 flash attention 等架构,该团队针对(2)(3)来设想 warmup 过程。具体的,在 warmup 阶段将 mask 比例上界安祥 warmup 到最大值,从而使得一出手任务从易变难。
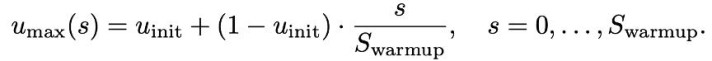
其次,在 warmup 阶段去掉交叉熵中加权的通盘,从而让每个 token 对 loss 的影响更沉稳:
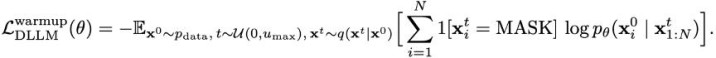
Block-wise 截断的噪声调节
在使用 block diffusion 时,由于通过 cross attention 拼接了干净的前缀,不错使得每个 token 都产生灵验的 loss。说合词若是使用传统的 noise schedule 会使得有些块不产生 loss 信号,通过求解积分不错算出 block 不产生信号的概率如下,这在小 block 时会非凡昭彰:
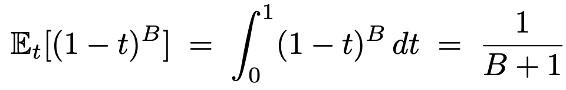
因此团队作念了两个设想:(1)强制每个块都采样一个 token(2)将 noise 采样下界建树为 1/B,这么不错使得至少生机采样一个 token。同期不错避将就制采样 1 个 token 之后,本来对应的 t 过小,从而使得交叉熵加权过大的问题。
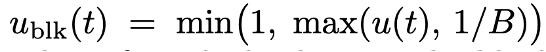
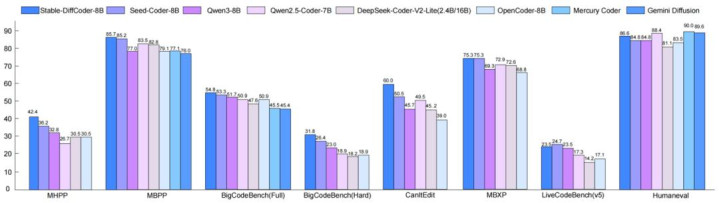
试验戒指:多个代码 benchmark 在 8B 傍边的模子保握最初
对于 Base 模子
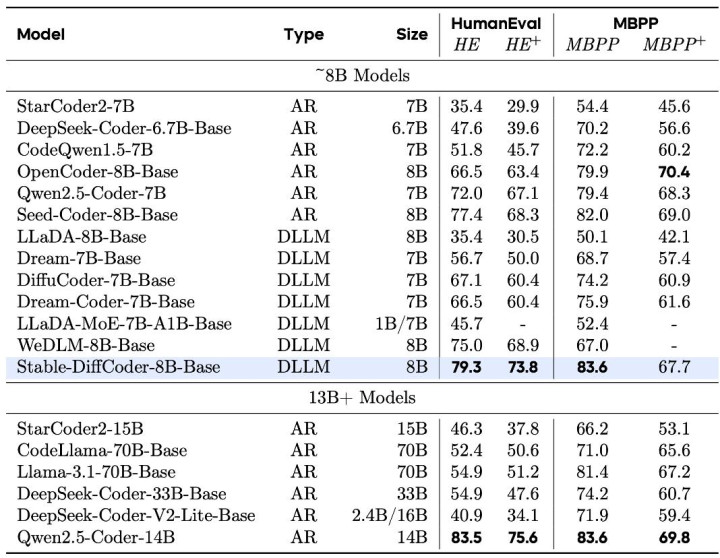
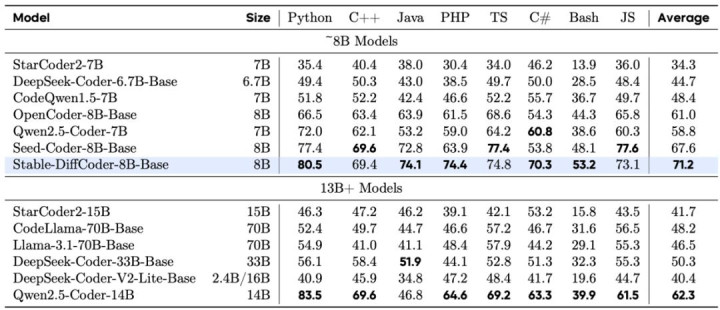
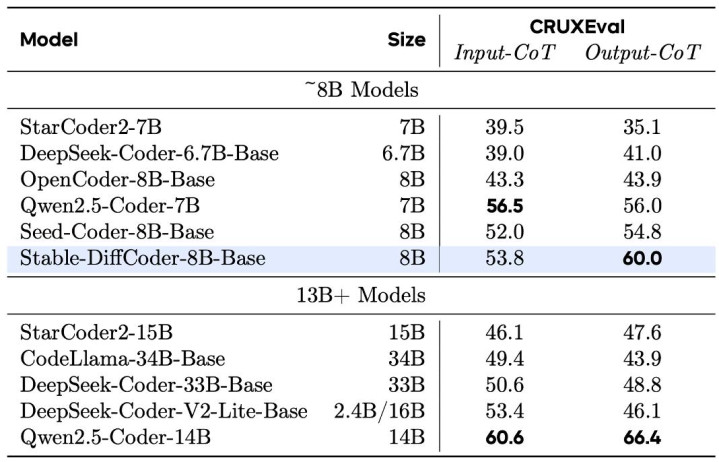
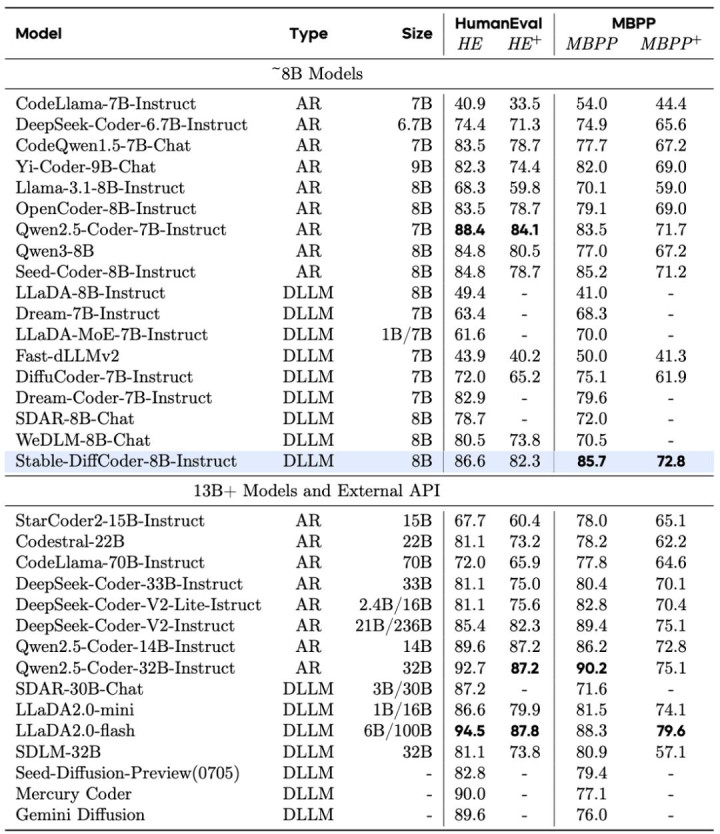
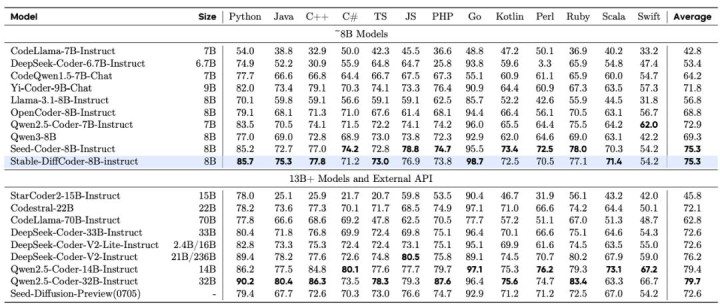
Stable-DiffCoder-8B-Base 在代码生成,多代码讲话生成,代码推理上发扬出色。卓越一系列 AR 和 diffusion-based 的模子。另外不错发现模子在零碎代码讲话上(如 C#,PHP 等,预锻练中数据较少),比较于 AR baseline 得到了大幅增强,不错讲明 DLLM 的锻练过程起到了一定的数据增强的后果。同期在代码推理材干上也得到了增强。
对于 Instruct 模子
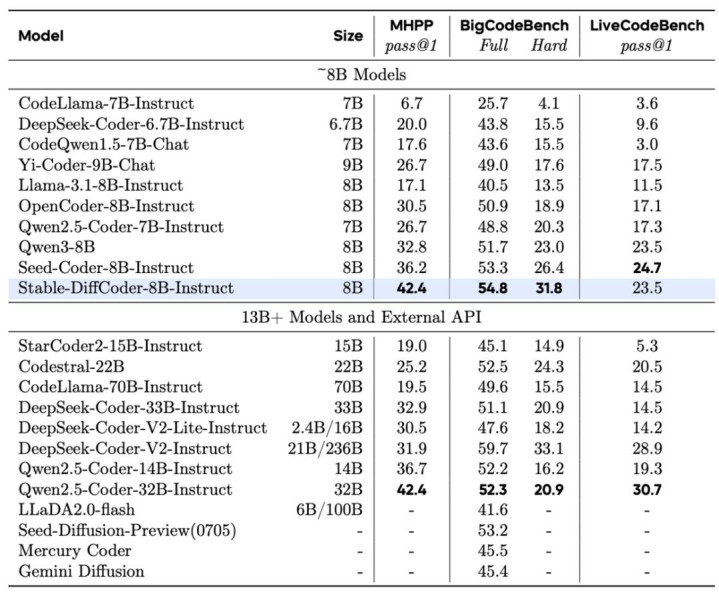
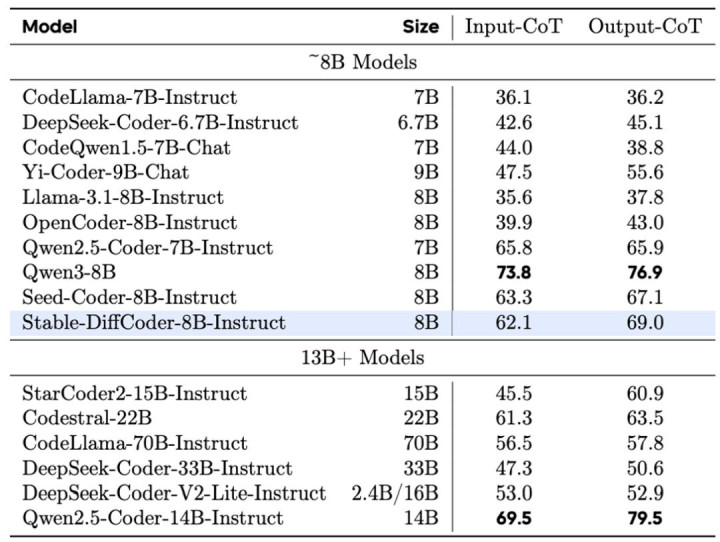
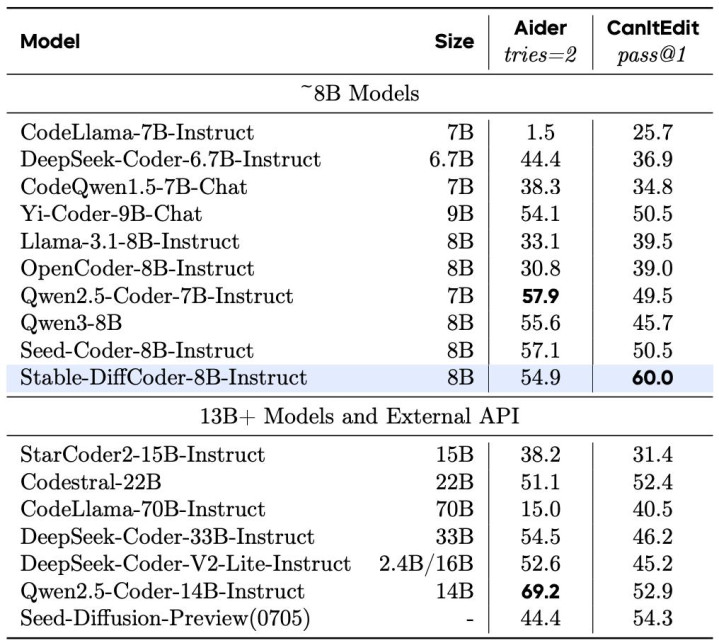
Stable-DiffCoder-8B-Instruct 在代码生成,代码裁剪,代码推理等任务上作念了详细评测,并有着优厚的发扬。其中在常用的任务(humaneval,mbpp)上大幅卓越原有 AR baseline 和其他 8B 傍边的 DLLM model。在测试集闭源的 MHPP 达到 qwen32B 的水平,BigCodeBench 上更是卓越一系列模子并仅次于 DeepSeek236B 的模子。同期在代码裁剪 CanItEdit 任务上更是有着惊艳的后果。
总结与瞻望
Stable-DiffCoder 的发布,冲破了 「扩散模子只可作念并行加快」 的刻板印象。它讲明了:扩散锻练范式自己即是一种极佳的表征学习时刻。通过合理的课程设想及踏实性优化,扩散模子全都不错在代码贯串和生成质料上超越传统的 AR 模子。
对于将来的大模子演进开云sports,Stable-DiffCoder 辅导了一条新旅途:也许咱们不需要根除 AR,而是将 AR 看成高效的学问压缩器,再期骗 Diffusion 看成 「强化剂」,进一步推高模子的智能上限。
 备案号:
备案号: