

[文/不雅察者网专栏作家心智不雅察所]开云体育
几天前,《Nature》杂志刊发了一篇来自中国的东说念主工智能策划论文。这在顶级学术期刊上并非极新事,但这篇论文的重量却非同小可:它来自北京智源东说念主工智能策划院,中枢效果是一个名为“Emu3”的多模态大模子,而它试图修起的问题,是系数AI领域已往五年来悬而未决的中枢命题——咱们能否用一种长入的步地,让机器同期学会看、听、说、写,乃至算作?
这个问题听起来浅薄,但它的复杂经由足以让大家顶尖的AI实验室争论禁止。
OpenAI用Sora惊艳寰宇,靠的是扩散模子;Google的Gemini整合多模态,用的是复杂的编码器拼接;Meta的Chameleon尝试长入,却遥远难以在性能上与专用模子抗衡。而智源的谜底,是一个看起来朴素得近乎偏激的弃取:只用“下一词展望”。
这个弃取的真谛,可能需要一些布景常识才能雄厚。

论文媒介
一场对于“谈话”的豪赌
淌若你问一位2020年的AI策划者,异日的多模态智能会是什么神态,他未必率会给出这么的展望:图像生成归图像生成,翰墨雄厚归翰墨雄厚,视频科罚归视频科罚,然后咱们用某种“胶水”把它们粘在系数。这不是懒惰,而是其时的期间现实——不同模态的数据特质互异太大,专精往往意味着高效。
事实上,这条门道在已往几年里获取了矍铄收效。StableDiffusion让无为东说念主也能生成惊艳的图像,GPT-4让对话AI变得无所不成,而多样视觉-谈话模子则在问答、识别、面孔等任务上接续刷新记载。但问题也随之而来:这些模子就像一个本领深湛但只会单项畅通的畅通员,让它们协同责任,需要复杂的工程架构、缜密的模态对皆,以及广泛的东说念主工热闹。
更要津的是,这种“专科化”的发展旅途隐含着一个令东说念主不安的假定:也许机器智能天生即是碎屑化的,咱们永远需要为每一种才智单独教练一个模子。
Emu3挑战的,恰是这个假定。
智源团队的中枢洞见是:淌若咱们把图像、视频、翰墨都治愈成归拢种“谈话”——闹翻的符号序列——那么让模子学习“展望下一个符号”这一个任务,是否就足以涵盖系数多模态才智(如下图)?
这个思法并非莫得前例。早在2020年,kaiyun sportsGPT-3就仍是解说,只是通过展望下一个词,谈话模子不错流露出惊东说念主的推理、翻译、编程才智。但将这一范式扩张到图像和视频,面对着天壤悬隔的挑战:一张512×512的图像,淌若用浅薄的步地治愈成符号,可能需要几十万个token,这对于Transformer架构来说是晦气性的计较包袱;更进击的是,图像的空间结构、视频的时刻集会性,与翰墨的线性叙事有着践诺永诀,浅薄的“下一词展望”简直能捕捉这些复杂的关系吗?
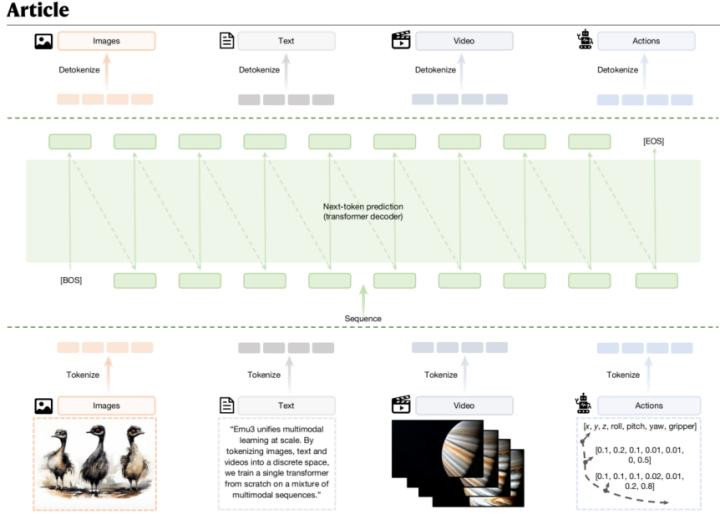
智源的谜底是确定的,而Emu3即是他们的解说。
简单来说:谁要是敢在网上公开唱衰楼市,谁要是敢主观引导房东降价,贝壳就要请谁“喝茶”,严重的话直接砸了饭碗。作为行业巨头的贝壳,为什么要在这个时候给几十万经纪人下达“禁言令”?
我们正在亲历一场大国崛起的底层重构,开云体育官方网站而普通人正在被推到命运重新分配的窗口边,这不是危言耸听,而是历史逻辑的必然回响。
一个分词器的艺术
措施会Emu3的期间突破,首先措施会它的“视觉分词器”(VisionTokenizer)。这个听起来不起眼的组件,践诺上是系数系统的基石。
思象一下,你需要用电报向一个从未见过图片的东说念主面孔一幅画。你不可能传输原始的像素值——那太冗长了;你也不成只说“一幅风景画”——那太微辞了。你需要的是一种既紧凑又糜掷发扬力的编码步地,能够在有限的符号中保留满盈的视觉信息。
Emu3的视觉分词器作念的恰是这件事。它能够将一张512×512的图像压缩成只是4096个闹翻符号,压缩比达到64:1;对于视频,它在时刻维度上进一步压缩4倍,使得一段4帧的视频片断也只需要4096个符号默示。这些符号来自一个包含32768个“词汇”的码本——你不错把它思象成一册视觉辞书,每个“词”代表一种特定的视觉模式。
更精妙的是,这个分词器是为视频原生估量打算的。传统的图像分词器科罚视频时,只可逐帧编码,完满忽略帧与帧之间的时刻联系;而Emu3的分词器通过三维卷积核,能够同期捕捉空间和时刻维度的信息。在实验中,这种估量打算用四分之一的符号数目,就达到了与逐帧科罚尽头的重建质地——这不仅意味着更高的效劳,更意味着模子能够信得过“雄厚”视频的动态践诺,而非只是科罚一堆静态图片。
有了这个分词器,图像和视频就酿成了与翰墨相同的符号序列。接下来的事情,即是让一个Transformer学会展望这些序列中的“下一个符号”。
当浅薄遇上限制
Emu3的模子架构,用一句话就能轮廓:它即是一个程序的大谈话模子,只不外词汇内外多了32768个视觉符号。
这种极简办法估量打算在AI策划界是荒凉的。主流的多模态模子——非论是LLaVA、BLIP-2如故Flamingo——都礼聘“编码器+谈话模子”的复合架构,即先用一个独特的视觉编码器(时常是CLIP)把图像治愈成特征向量,再用适配器将这些特征“注入”谈话模子。这种估量打算的克己是不错复用已有的预教练组件,但代价是系统复杂度的急剧高涨,以及模态之间潜在的隔膜——视觉编码器寝兵话模子毕竟是独处教练的,它们对寰宇的雄厚未必一致。
Emu3弃取了一条更激进的路:无谓任何预教练的视觉编码器,无谓任何复杂的模态会通机制,只用一个从零运行教练的decoder-onlyTransformer。系数的多模态常识,都是在长入的下一词展望任务中从数据里学来的。
这种“正途至简”的估量打算形而上学,在实施中转机为了惊东说念主的实验罢休。
在图像生成任务上,Emu3在东说念主类偏好评估中得分70.0,高出了StableDiffusionXL(66.9)这个扩散模子的标杆;在视觉谈话雄厚的12个基准测试上,它的对等分达到62.1,与礼聘复杂编码器架构的LLaVA-1.6(61.8)捏平;在视频生成的VBench评估中,它获取了81.0分,最初了独特的视频扩散模子Open-Sora-1.2(79.8)。
这些数字的真谛在于:一个只是用“展望下一个符号”教练的模子,在生成和雄厚两个看似矛盾的方进取,同期达到了专用模子的水平。这在此前被觉得是不可能的——毕竟,扩散模子和自转头模子的数学基础完满不同,擅长雄厚的架构时常不擅永生成,反之也是。Emu3的收效,尽头于一个畅通员同期在短跑和马拉松比赛中夺冠开云体育,冲破的不仅是记录,更是东说念主们对专科化规模的明白。
 备案号:
备案号: