

允中 发自 凹非寺
国产算力基建跑了这样多年,寰球最面孔的逻辑一直没变:芯片够不够多?
但对斥地者来说,真是扎心的问题其实是:好不好使?
淌若把AI斥地比作作念饭,咫尺的狼狈是——
国产锅(硬件)天然越来越多了,但大部分大厨如故只习气用那套入口调料包(生态)。
这恰是当下AI落地最真实的一幕。
模子层似锦似锦,底层却隐忧重重。寰球在参数范畴上轮替刷新记载,回及其来却发现,最难懂脱的如故那套还是前途骨子里的斥地经过。
△图片由AI生成
算力仅仅垫脚石,真是的赢输手,是那段算法与硬件之间的“翻译权”。
说白了,淌若拿不到这支“翻译笔”,再强悍的国产硬件,也只可像是一座无法与外界疏通的孤岛。
终于,阿谁闪斥地者喊了无数次“全国苦CUDA久矣”的僵局,咫尺迎来了一个不一样的国产谜底。
KernelCAT:意象加快大众级别的Agent
这几年,AI鸿沟的侵扰简直是肉眼可见的。
模子在密集发布,诳骗数据捏续走高,看上去一切齐在加快上前。
但在工程现场,感受却更复杂。
真是制约落地效果的,并不是模子智商自身,而是底层软件生态的熏陶度。
硬件取舍一多,问题反而围聚暴线路来:移动老本高,适配周期长,性能开释不安然。许多模子即便具备要求切换算力平台,最终也会被算子因循和器用链完好度挡在门外。
这让一个事实变得越来越明晰——冲突口不在堆更多算力,而在买通算法到硬件之间那段最容易被疏远的工程链路,把芯片的表面性能真是升沉为可用性能。
其中最关节的一环,恰是高性能算子的斥地。
算子(Kernel),是调处AI算法与意象芯片的“翻译官”:它将算法升沉为硬件可实施的指示,决定了AI模子的推理速率、能耗与兼容性。
算子斥地不错被领路为内核级别的编程职责,咫尺行业仍停留在“手职责坊”期间——斥地过程相配依赖顶尖工程师的教养与反复试错,周期动辄数月,性能调优如同在迷雾中摸索。
若把斥地大模子诳骗比作“在精装修的样板间里摆放居品”,那么编写底层算子的难度,无异于“在深海中戴着千里重的手铐,徒手拼装一块精密机械表”。
但淌若,让AI来斥地算子呢?
传统大模子或学问增强型Agent在此类任务眼前通常力不从心。因为它们擅长模式匹配,却难以领路复杂意象任务中的物理料理、内存布局与并行退换逻辑。
独一超过教养式推理,深刻建模问题本色,才气兑现真是的“智能级”优化。
恰是在这一“地狱级”手艺挑战下,KernelCAT应时而生。
△终局版
具体来看,KernelCAT是一款腹地启动的AI Agent,它不仅是深耕算子斥地和模子移动的“意象加快大众”,也未必胜任平日通用的全栈斥地任务,提供了CLI终局号召行版与粗略桌面版两种方式供斥地者使用。
不同于仅聚焦特定任务的器用型Agent,KernelCAT具备塌实的通用编程智商——不仅能领路、生成和优化内核级别代码,也能处理惯例软件工程任务,如环境确立、依赖管理、差错会诊与剧本编写,从而在复杂场景中兑现端到端自主闭环。
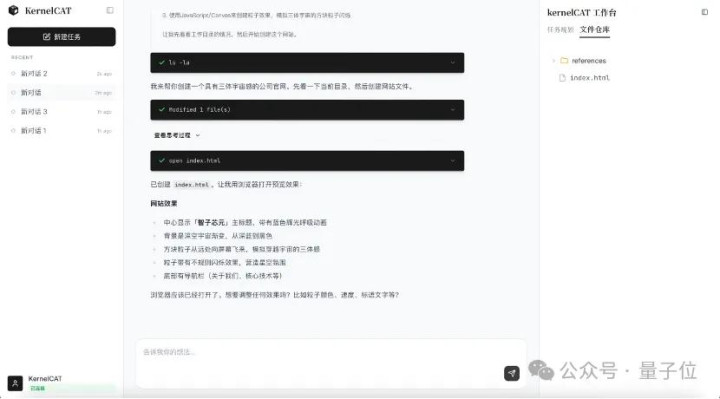
△桌面版
为国产芯片生态写高性能算子
在算子斥地中,有一类问题很像“调参”——靠近几十上百种参数或计谋组合,工程师需要找出让算子跑得最快的那一组确立。
传统作念法靠教养试错,费时致力于,何况还容易踩坑。
KernelCAT的想路是——引入运筹优化,把“找最优参数”这件事交给算法,让算法去探索调优空间并拘谨到最好决策。
以昇腾芯片上的FlashAttentionScore算子为例,KernelCAT在昇腾官方示例代码上,不错自动对该算子的分块参数调优问题进走运筹学建模,并使用数学优化算法求解,在十几轮迭代后就锁定了最优确立,kaiyun sports在多种输入尺寸下延长诽谤最高可达22%,费解量进步最高近30%,何况总共这个词过程无需东说念主工骚扰。
这恰是KernelCAT的特有之处:它不仅具备大模子的智能,未必领路代码、生成决策;还领有运筹优化算法的严谨,未必系统搜索并拘谨到最优解。
智能与算法的市欢,让算子调优既无邪,又有托付保险。
在对KernelCAT的另一场测试中,该团队选取了7个不同范畴的向量加法任务,测试看法明确——
即在华为昇腾平台上,获胜对比华为开源算子、“黑盒”封装的生意化算子与KernelCAT自研算子兑现的实施效果。
遗弃相同令东说念主激越,在这个案例的7个测试范畴中,KernelCAT给出的算子版人道能均赢得起首上风,且任务完成仅用时10分钟。
这意味着,即便靠近经过生意级调优的闭源兑现,KernelCAT所遴选的优化形势仍具备一定竞争力。
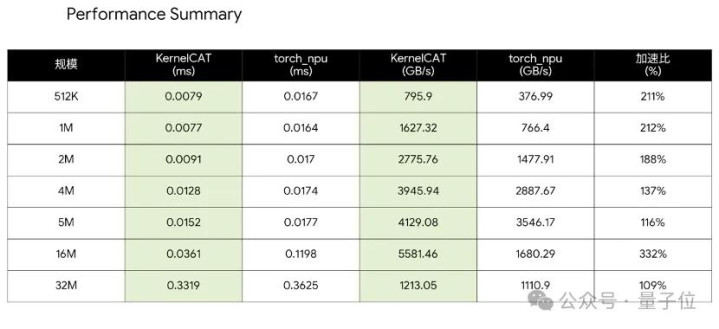
这不仅是数值层面的到手,更是国产AI Agent在算子鸿沟完成的一次自证。


莫得坚不行破的生态,包括CUDA
全球范围内,咫尺越过90%的不毛AI查考任务启动于英伟达GPU之上,推理占比亦达80%以上;其斥地者生态遮蔽超590万用户,算子库范畴逾400个,深度镶嵌90%顶级AI学术论文的兑现经过。
黄仁勋曾言:
咱们创立英伟达,是为了加快软件,芯片遐想反而是次要的。
这句话揭示了一个关节真相:在当代意象体系中,软件才是真是的护城河。
英伟达的捏续起首,源于其从底层算法开赴、解析架构与编程模子的全栈掌控智商。
参考AMD的历史教养,即使在架构与制程上具备充足的竞争力,阑珊熏陶的生态系统也仍然难以撼动英伟达的地位。
这类案例明晰地标明,模子性能并不简短等价于算力范畴的堆叠,而是取决于算法遐想、算子兑现与硬件特点的协同进程。当算子实足熏陶,硬件后劲才气被真是开释。
沿着这条想路,KernelCAT团队围绕模子在原土算力平台上的高效移动,进行了系统性的工程探索。
以DeepSeek-OCR-2模子在华为昇腾910B2 NPU上的部署为例,KernelCAT展示了一种全新的职责范式:
挣扎“版腹地狱”:KernelCAT对任务看法和收尾要求有着深度领路,基于DeepSeek-OCR-2官方的CUDA兑现,通过精确的依赖识别和补丁注入,惩处了vLLM、torch和torch_npu的各个依赖库间版块互锁的三角矛盾,硬生生从零搭建起了一套安然的坐褥环境,市欢基础Docker镜像即可兑现模子的开箱即用。
准确修补:它犀利地识别出原版vLLM的MOE层依赖CUDA专有的操作,和vllm-ascend提供的Ascend原生MOE兑现,并飘摇通过插件包进行调用替换,让模子在国产芯片上“说上了母语”。
兑现35倍加快:在引入vllm-ascend原生MOE兑现补丁后,vLLM在高并发下的费解量飙升至550.45toks/s,比较Transformers决策兑现了35倍加快,且在连接优化中。
无需东说念主工多数介入:在这种复杂任务看法下,KernelCAT不错我方计算和完成任务,无需研发提供多数领导词疏导模子职责。
这意味着,正本需要顶尖工程师团队破耗数周才气完成进行的适配职责,咫尺不错缩小至小时级(包含模子下载、环境构建的时辰)。
与此同期,它让国产芯片从“能跑”到“飞起”,兑现了35倍的加快。
也即是说,KernelCAT让国产芯片不再是被“封印”的算力废铁,而是不错通过深度工程优化,承载顶级多模态模子推理任务的性能引擎。

“全国苦CUDA久矣”——这句话曾是无奈的自嘲,如今正成为看成的军号。
KernelCAT所代表的,不仅仅一个AI Agent新范式的出现,更是一种底层智商成立形势的转向:
从依赖既有生态,到构建未必自我演进的意象基础。
KernelCAT正限时免费内测中开云sports,迎接体验:https://kernelcat.cn/
 备案号:
备案号: