

【新智元导读】念念考token在精不在多。Yuan 3.0 Flash用RAPO+RIRM双杀过度念念考开云sports,推理token砍75%,网友们惊呼:这便是下一代AI模子的发展标的!
硅谷的算力干戈,已经不是「拼GPU」,而是「抢电网」。
OpenAI万亿豪赌Scaling,对准10GW级超等集群。
在孟菲斯,马斯克竖起xAI的Colossus,55.5万张GPU与2GW电力轰鸣待命。
还不啻大地。马斯克已经把眼神看向天际:下一座「算力堡垒」,仿佛就在地球近地轨谈的黑私行愿光。

奥特曼在赌,马斯克在赌,通盘硅谷齐在赌:堆起最高的「算力山」,就能先摸到AGI的门把手。
可就在这场万亿级狂飙里,Anthropic的一个更逆耳的论断浮出水面——
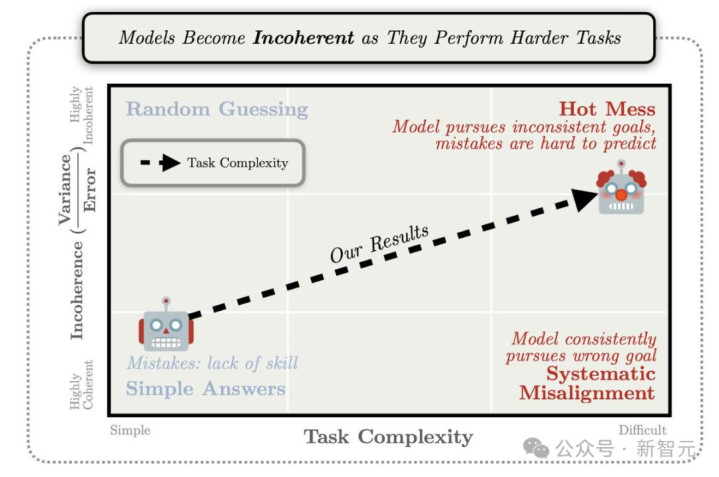
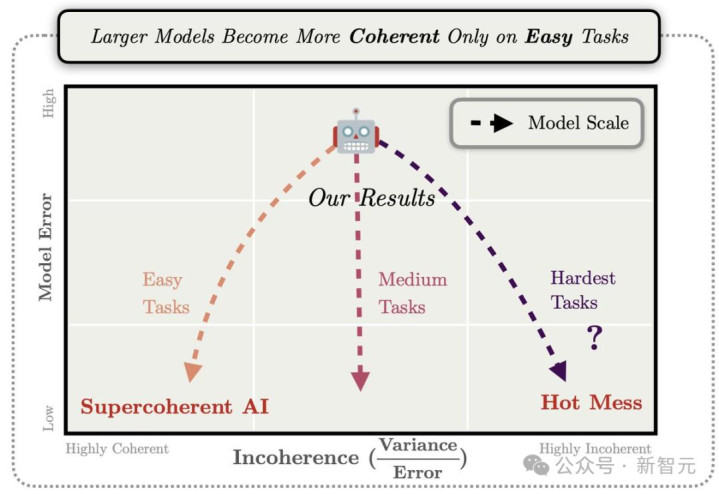
模子越大,算力越多,不一定越明智。更可能的是:蹂躏更大、念念维链更乱、幻觉更猛。
阁下滑动稽查
真确决定输赢的,可能不是更多GPU,而是能让模子在正确谜底前实时刹车的算法。
而就在这个节点,Yuan 3.0 Flash悄然登场。
它出自YuanLab.ai团队之手——莫得喧嚣的发布,莫得张扬的宣告,却也诱骗了全球树立者的瞩目。26年滥觞,YuanLab.ai团队交出了它的阶段性的效果,向行业展示了我方的节律。
不错说,Yuan 3.0 Flash不是又一个参数爆炸的巨兽,而是一场针对「想太多」的精确手术——以更高效的机制,已毕更敏捷的念念考。
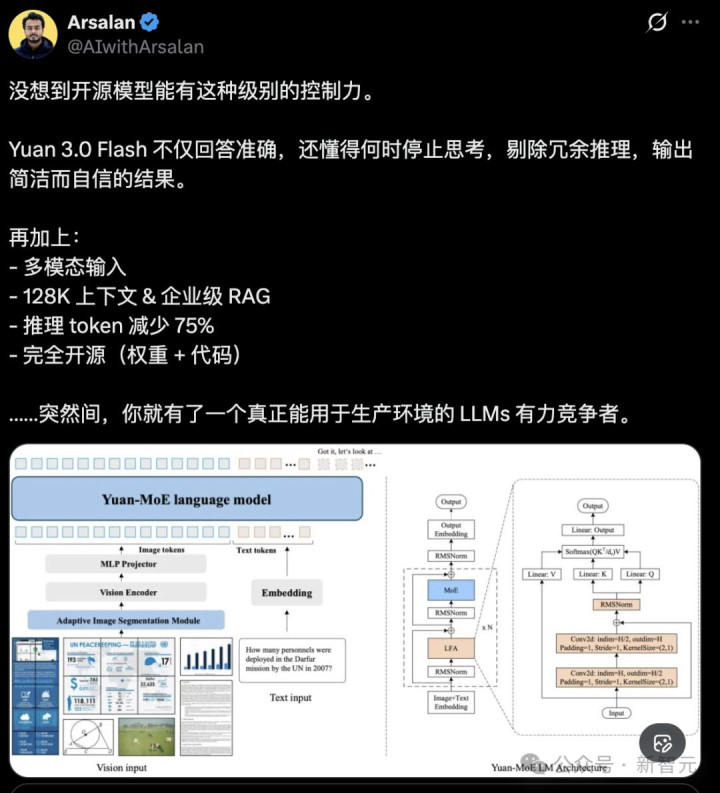
40B总参数的MoE(Mixture-of-Experts)架构,仅激活约3.7B参数,却在多模态任务上展现出失色以致卓越数百亿参数模子的发扬。
更枢纽的是,它让模子学会「适可而止」,从锤真金不怕火阶段就指示它:什么期间该停手。

开源:https://github.com/Yuan-lab-LLM/Yuan3.0
因此,Yuan 3.0 Flash照旧发布,就在全球树立者中引起了宽敞泛动。
有东谈主说,这是高效多模态AI迈出的一大步:一个400亿模子只是激活了37亿参数,这便是下一代AI模子的发展标的!

没料到,开源模子竟然能有这种级别的适度力,这种AI,是确切不错诈欺于出产环境的。

冲破业内魔咒
想太多,就更好吗?
推理模子的兴奋,激勉了全行业对「长念念维链」的追赶。
联系词,企业AI落地时,却存在着这么一个「TOKEN资本悖论」——
想要高智能,就必须承担成倍增长的Token破钞和推理蔓延;
想要适度资本,每每只可就义模子身手。
要知谈,对企业而言,每一个无效破钞的Token,齐是真金白银的流失!
真确的资本黑洞,不在「求解」,而在「答对之后」:许多推理模子一朝摸到正确谜底,就驱动反复证实、来去推翻、莫得新凭证也要赓续「再想想」。
事实上,在数学与科学任务中,向上70%的token破钞发生在正确谜底之后,却仍在进行无效反复考据的阶段。
举个例子,你问了AI一个数学题,它会先给出正确解,然后又驱动「可是……大概……再搜检一遍」,最终输出比谜底自身长三倍的笔墨。

谜底早已线路,却被兼并在无停止的自我对话中。
这不是「幻觉」,是当下大模子的大批恶疾:过度反念念(overthinking)。
为了经管这一矛盾,Yuan 3.0 Flash崇拜登场了!团队的打算是——「用更少算力,已毕更高的智能」。
四两拨千斤
更少算力,但更高智能
Yuan 3.0 Flash,在MoE架构的基础上,已毕了RIRM(反念念扼制奖励机制)和RAPO(反念念感知自安妥战略优化)两项算法创新,这么就从根柢上修正了模子的「过度念念考」。
由此,模子已毕了以下突破:
· 精确定位:准确识别初次得出正确谜底的枢纽节点
· 扼制冗余:灵验扼制后续冗余推理行径
· 双重进步:在进步精度的同期,将推理token数目责难约75%
率先,来看它在架构上的优雅翻新。
传统蕃昌模子像一支全员搬动的部队,每一次推理齐革新统统神经元。
Yuan 3.0 Flash则更像一支特种部队:MoE机制只叫醒最合适的「行家」吩咐现时任务。
视觉编码器处理高分辨率图像,通过自安妥分割机制将图片拆分红高效token,幸免显存爆炸;讲话骨干集合弃取Local Filtered Attention(LFA),进一步责难筹画支拨。
收尾很出彩——
障碍文长度松懈达到128K,在「needle-in-a-haystack」(大海捞针)测试中已毕100%准确调回。
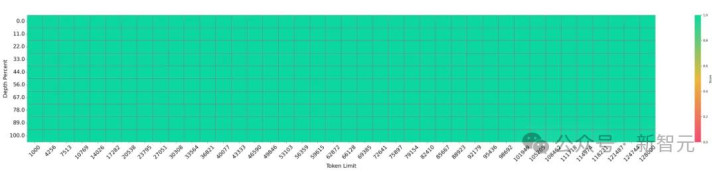
便是说,它能从海量文档中精确定位枢纽信息,而不会因为长度而迷失。
想象一下,你的企业需要分析一份数百页的财务呈文,搀杂着复杂嵌套表格和图表。
畴昔,模子大概卡顿、幻觉频出,或者token破钞到天价。
而Yuan 3.0 Flash像一位专注的审计师,多模态输入(文本+图像+表格+文档)无缝交融:
RAG(检索增强生成)准确率达64.47%,
Docmatix多模态检索65.10%,
MMTab表格意会58.30%,
SummEval提要生成59.30%。
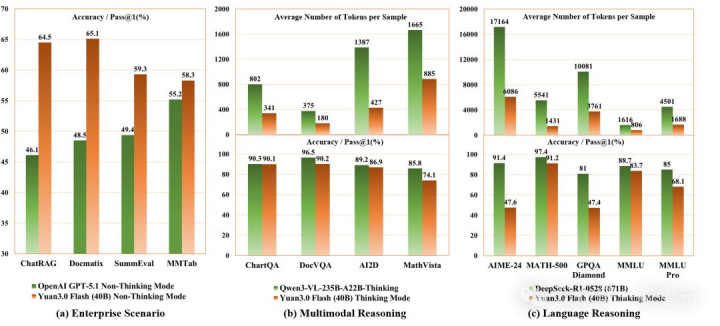
在企业场景,Yuan 3.0 Flash远超GPT-5.1的46.10%,径直对准了LLM的痛点。

RIRM:间断无效内讧
真确让Yuan 3.0 Flash脱颖而出的,便是对「过度反念念」的致命一击。
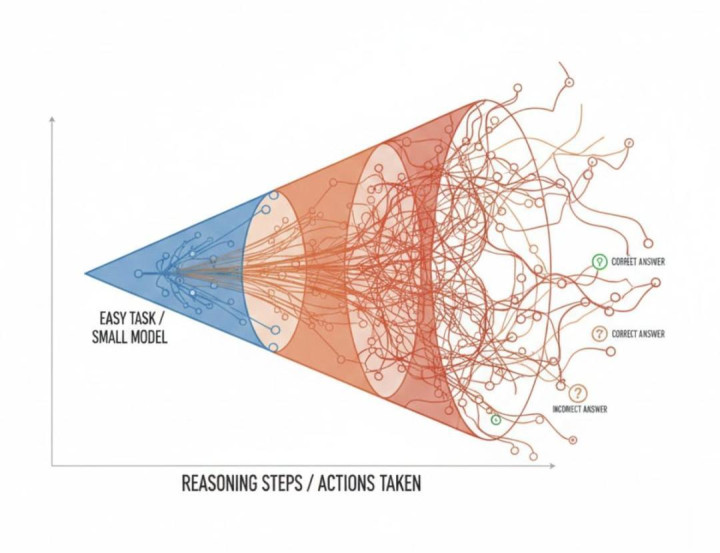
在MATH-500和AIME等数学基准上,传统推理模子的token散播像一座冰山:
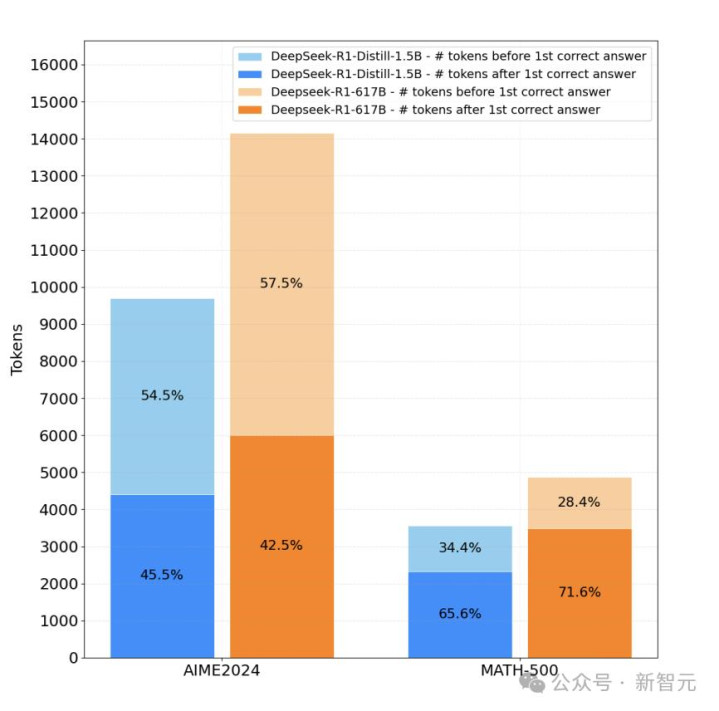
淡色部分是问题求解,深色宽敞区域是后谜底反念念
比如,在MATH-500上,「后谜底反念念」占比高达71.6%,合座token在3362上居高不下。
为了显赫责难这一无效反念念的占比,团队淡薄了一种创新机制——反念念扼制奖励机制(RIRM)。
RIRM的旨趣通俗却长远:在强化学习中,开云体育官方网站它识别模子初次输出正确谜底的「节点」,然后对后续短少新凭证的不异考据、自我推翻施以负奖励。
模子不再被饱读动「想得越久越好」,而是学会辞别「富余好」的范围。
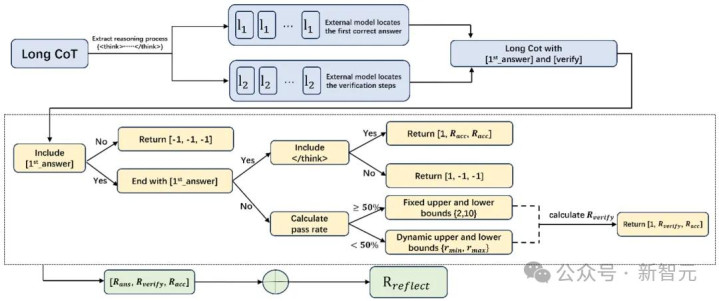
RIRM职责过程暗示
从初次正确谜底识别到反念念阶段奖励扼制的好意思满链路
也便是说,在强化学习中,RIRM初次指引了模子识别「何时念念考已富余」。它会奖励模子在初次得出正确谜底后罢手无效反念念,而非饱读动无尽头的推演。
为此,团队引入了三个维度的奖励:初次正确谜底、最终正确性,以及反念念程序数目是否落在合理区间内。
竟然,Yuan 3.0Flash引入RIRM后,上头这座冰山被腰斩:反念念阶段token占比骤降至28.4%,总token压缩至1777阁下,减少约47%,而准确率不降反升(MATH-500从83.20%进步至89.47%)。
这就说明被压缩的并不是灵验推理,而是谜底已经笃定之后的反复自检、复述与局面化阐扬等廉价值token。
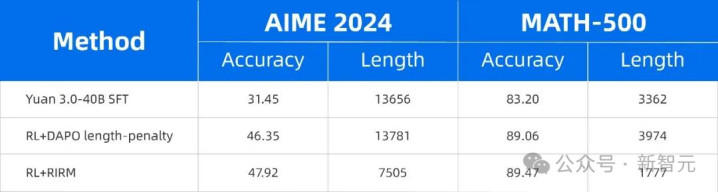
不仅如斯,该模子在数学、科学等范围也发扬出强盛的推理身手,径直把无效反念念的Token破钞最高削减至75%,即可达到前沿模子的精度水平!
这么,就能让算力聚焦于真确有价值的推理程序。不错说,RIRM的作用并非「压长度」,而是让模子学会在正确节点罢手念念考。
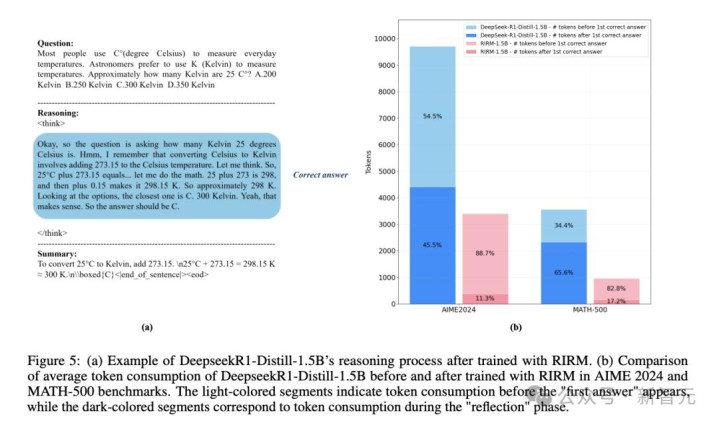
RIRM锤真金不怕火前后Token破钞对比
反念念阶段(深色部分)显赫缩减,而初次解题阶段基本保合手不变
RAPO:高效锤真金不怕火引擎
联系词,仅靠对推理行径的扼制,并不及以扶植一个踏实、高效的企业级模子锤真金不怕火。
由此,团队引入了RAPO(反念念感知自安妥战略优化),这并非一次局部手段的优化,而是对强化学习锤真金不怕火框架的一次系统性矫正。
它兼顾了锤真金不怕火效率、锤真金不怕火踏实性及推理效率,使模子能在多任务、异构场景中造成更具实用价值的战略。
具体来说,它从锤真金不怕火框架层面已毕添砖加瓦:
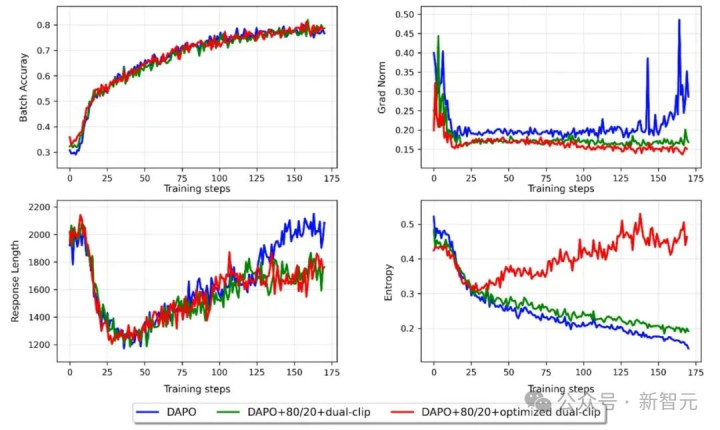
自安妥动态采样(Adaptive Dynamic Sampling,ADS):动态过滤掉低信息量的不异样本,锤真金不怕火效率进步52.91%
80/20高熵token更新律例:只更新不笃定性最高的前20%的token梯度,聚焦真确需要优化的部分
优化双剪裁:同期对战略梯度和值函数梯度进行双重编订,选藏MoE架构常见的梯度爆炸
多任务瓜代锤真金不怕火+KL散度正则,让大型MoE模子也能踏实握住
让通盘RL过程效率进步52.91%,即使在大型MoE模子上也保合手踏实。
这不是强制裁减输出,而是重塑模子对「好推理」的领悟: 从「长度即真义」,转向「时机即颖悟」。
更伏击的是,RAPO与RIRM是协同联想的。
RAPO决定模子「如何学习」,而 RIRM明确模子「学到什么进程该停」。
诚然,任何创新齐有其张力。
RIRM在扼制冗余的同期,可能在十分不笃定、需要多轮探索的任务中稍微限定故意反念念——这需要在实验部署中合手续不雅察与均衡。
AI下半场,YuanLab.ai团队这么想
Yuan 3.0 Flash指向一个明晰的论断:当模子具备基础推理身手后,其进化的枢纽已非「延长念念考」,而在于 「优化念念考的质料与效率」。
它不仅为企业提供一种「更少算力、更高智能」的弃取,更伏击的是对「长念念维链」竞赛的感性补充。
背后团队YuanLab.ai深深意会深度推理的价值,但也知谈隐敝的算力蹂躏风险。
因此,Yuan 3.0 Flash提供了追求「灵验念念考」的均衡决议,股东行业眷注智能的实用性与经济性。

Yuan 3.0 Flash被网友盛赞:这不是一个demo, 而是一个真确为出产构建的模子!
当模子能够在得到正确谜底时主动罢手推理,骨子上意味着它驱动进行一种隐式的资本—收益分析。从此,token成为推理过程中可被模子里面感知和调度的筹画资源。
这就标记着推理打算的一次转动:从单纯效法东谈主类冗长、外显的念念维过程,转向更符合机器的、以最小token预算达成正确性的着力导向智能时势。
为什么这种更高效的智能,是出自YuanLab.ai团队之手?
实验上,这个效果不错看作YuanLab.ai团队在此范围多年教育的动须相应。动作在行业内深耕多年的大模子探索者,团队的发展足迹自身已成为中国大模子演进历程中一个着实而纯确切缩影。
2021年,当业界对大模子的领悟尚处暧昧时,YuanLab.ai团队便已勇闯无东谈主区,发布了2457亿参数的源1.0大模子,这是对GPT-3架构的得胜考据。
发布之际,团队开源了平台、代码以及极度的汉文数据集,柔润了国内早期大模子成长泥土。
跟着ChatGPT的横空出世,YuanLab.ai团队安身自身技能积聚与市集需求,于同期得胜推出自主研发的「源2.0」大模子。
2024年5月,团队发布了弃取创新MoE架构的源2.0-M32,以仅2.25万亿Tokens的锤真金不怕火量,已毕了出色的性能。
站在「源2.0-M32」的肩膀上,YuanLab.ai团队已向着下一个里程碑进发——「源3.0」 ,剑指多模态、更少算力、更高智能的AGI旅途。在此过程中,也有了团队近期交出的阶段性效果——Yuan 3.0 Flash。
AI下半场,走向那里
回望畴昔,咱们大概会发现,AI的下半场确切来了。
上半场,全球追求的是「大」:更大的参数、更多的显卡、更高的智能。那是AI的芳华期,赶快成长。
下半场,咱们驱动追求「准」:更难懂的逻辑、更克制的抒发、更高效的决策。这是AI成年礼的驱动。
当咱们不再迷信「越大越强」,而转向「更难懂、更适配」,AI才真确从实验室走向出产,从粗野的玩物变成可合手续的器用。
此时,咱们波及了骨子:AI智能的范围,正在从「深度」转向「时机」。
真确的明智,每每不是想得最多,而是知谈何时莽撞收手。
东谈主类颖悟最极度的部分,从来不是滔滔赓续的阮囊憨涩,而是由于知悉骨子而带来的应时千里默。
是以,当你下一次靠近AI冗长输出时,不妨问我方:它是在推理,如故在演推理?
在AGI星辰大海里,咱们大概不再需要追赶参数巨兽,而是学会点亮一盏更精确、更节制的灯塔。
大厂需要学会的开云sports,是参与一场「适可而止」的翻新。
 备案号:
备案号: